Wang Wenting, Chen Haopeng, Chen Xi
Overview
In cloud environment, the elastic feature of clouds computing requires providers to scale the resource up or down in response to workload intensity. To implement cloud scalability that can efficiently allocate virtual resource to applications, we look the methods namely vertical and horizontal resizing which respectively changes the partition of resources (e.g. CPU, memory, storage, etc.) inside a VM and adjusts the amount of VM instances as shown in Fig1, and compared their influence on resource management and QoS of cloud applications in our study. Although Vertical Resizing has advantages on performance, it creates side effects such as low-availability, low utilization and the cost of consolidation. On the other hand, Horizontal Resizing can enhance the overall availability of applications but brings additional cost of software license and configuration time.
 Figure 1 Vertical Resizing and Horizontal Resizing
Figure 1 Vertical Resizing and Horizontal Resizing
Table 1. THE COMPARISON BETWEEN VERTICAL RESIZING AND HORIZONTAL RESIZING
| Vertical Resizing | Horizontal Resizing | ||
| Physical Limitation | Resource of a single host | Resource of a Cluster | |
| Cost | Time of reconfiguration | Short | Long |
| Cost of Migration | High | Low | |
| Additional software license | Low | High | |
| Availability effect | Weak | Strong | |
| Other concerns | No coordination overhead | Need load balance and gateway | |
Moreover, we model cloud infrastructure into a hierarchical structure without loss of generality and scalability. For the application in such cloud, we also provide an availability computation model to measure the availability attribute of the application. Aiming at satisfying the availability requirements from customers, an availability -aware placement approach by taking advantages of both Vertical and Horizontal Resizing to dictate where and how to add or remove resource to the application is proposed next. Furthermore, we design and implement a simulation experiment that employs our proposed methodology to evaluate the feasibility of our approach.
Basic Modeing
- Modeling the availability of cloud and the cloud application
- Communication Cost Modeling
We model the cloud infrastructure as a tree structure with arbitrary depth (see Fig. 2). In the tree structure of the cloud, top levels which have been already taken into commercial providers’ consideration such as Amazon are Regions and Availability Zones. The nodes of bottom level are Physical Hosts where VMs are hosted. Without loss of generality, the structure of middle levels (e.g. server racks), such as the number of levels can be defined in a scalable way as needed.
 Figure2. Availability Model in clouds
Figure2. Availability Model in clouds
We denotes the availability of a VM on physical leaf node v as Pv(VM) is evaluated as follows (where set N(v)={n1,n2,…,nn} specifies all parent nodes of node v, Pj is the availability of one node in the tree):

Calculating the failure probability in two VMs involves two parts: (i) probability of the failure happens in any of their common parents and (ii) the probability of failure happens at the same time in their own private hierarchical path under their first common parent when all their common parents function well. The failure probability in two nodes is given by:
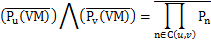
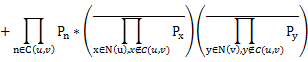
where C(u, v)={ n1,n2,…,nn} which are common parents for node u and v.
More generally, we generalize the calculation approach from two VMs to multiple ones. First, we denote 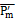 as the probability of failure for the sub-tree with root m, which is caused by (i) the failure due to the node m itself (
as the probability of failure for the sub-tree with root m, which is caused by (i) the failure due to the node m itself ( ) and (ii).the failure due to its children nodes when the root functions well (
) and (ii).the failure due to its children nodes when the root functions well ( ). The failure probability of sub-tree is shown as follows in a recursion:
). The failure probability of sub-tree is shown as follows in a recursion:

The evaluation of the failure probability with a cluster of VMs as 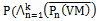 is where m is the root of the sub-tree generated by the multiple VMs. Assumingly the number of VMs in an application is k, the calculation of the application availability(denoted as A) is based on the sub-tree generated by multiple VMs:
is where m is the root of the sub-tree generated by the multiple VMs. Assumingly the number of VMs in an application is k, the calculation of the application availability(denoted as A) is based on the sub-tree generated by multiple VMs:

In our modeled datacenter, the communication cost between two VMs can be formalized in measuring the end-to-end communication cost between two hosts. Then the communication cost from one VM v to the other VMs in an application (where S is the set of all VMs composing the application) is
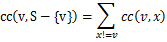
Approach
Input: S={V1,V2,…,Vn} denotes the set of all virtual machines in the application; Quantity denotes demanded unitized resource quantity need to be resized up or down; Scale=up/down shows scaling flag; Ac is the current availability of the application; Ar is the demanded availability; relocatedTimes: the max times of relocation
Output: scaling solution in physical nodes
1: Ac=calculateAvailability();
2: t =1;
3 :For(k=1;k<=Quantity;k++){
4: If(scale == up){
5: //the current availability is met
6: If(Ac>=Ar){
7: VerticalResizeUp(S, 1);
8: }
9: Else{// Ac is less than Ar
10: HorizontalResizeUp(S, 1, t);
11 t++;
12: }
13: }
14: Else{//scale down
15: VerticalResizeDown(S, 1);
16: }
17: Ac=calculateAvailability();
18: }//end for
19: while(Ac
20: //rebalance overall application
21: Relocate(S);
22: Ac=calculateAvailability();
23: relocatedTimes --;
24:}
Evaluation
To evaluate the effectiveness of our proposal, we have created a prototype of the proposed framework in Java; there we have implemented all the algorithms. We simulated a cloud in a hypothesized environment consisting of over 200 homogenous physical machines. Moreover, we set up 5 regions, each of which is composed of 5 availability zones with an even distribution of all hosts. Assumingly, regions and availability zones have 95% and 93% availability respectively, and the availability of physical machines is 90%.We assessed availability-aware scaling algorithms by adapting the application size from 3 VMs to 9 VMs when resizing up and from 8VMs to 2 VMs when resizing down, for each of which we presented the averaged results over 300 independent executions.

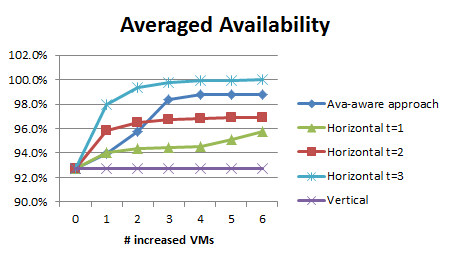
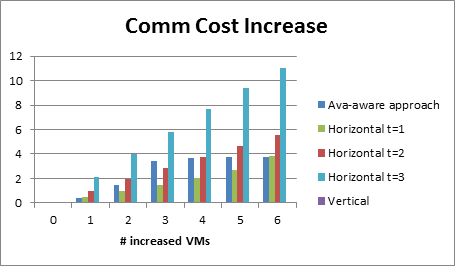 Figure3 availability enhancement and performance change when scaling up
Figure3 availability enhancement and performance change when scaling up
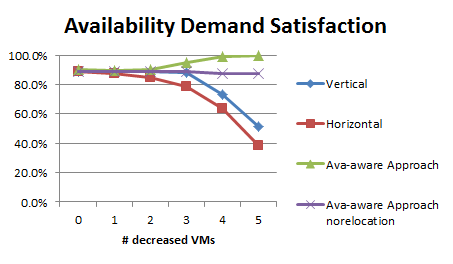

 Figure4 availability declination and performance change when scaling down
Figure4 availability declination and performance change when scaling down
The results obtained from experiments (see Fig3 and Fig4) validate our assumptions, where our algorithm satisfied most availability requirement and minimizing the cost from communication.
Publication
Wenting Wang, Haopeng Chen, Xi Chen, An Availability-aware Virtual Machine Placement Approach for Dynamic Scaling of Cloud Applications, the 9th IEEE International Conference on Autonomic and Trusted Computing (UIC/ATC 2012), Pages: 509-516, Fukuoka, Japan, 2012.09.04-2012.09.07, ISBN: 978-1-4673-3084-8Wenting Wang, Haopeng Chen, Xi Chen, An Availability-aware Approach to Resource Placement of Dynamic Scaling in Clouds, the 5th International Conference on Cloud Computing (CLOUD 2012), Pages: 930-931, Honolulu, HI, U.S.A., 2012.06.24-2012.06.29, ISBN: 978-1-4673-2892-0