Wang Yisheng, Chen Haopeng
Sponsored by the Graduate School of Shanghai Jiao Tong University (985 Program)
Overview
Cloud Federation is proposed as the next hot-spot in Cloud researching field, but researchers do not reach an agreement in details. Many new terms have then been coined as “Intercloud” or “Cross-cloud”. The ultimate goal of Cloud Federation is to enable message transmission and collaboration among Clouds so that resources located in different Cloud platform can be used to serve a single service. Cloud can ‘borrow’ some virtualized resources from other Clouds. Similarly, free resources can also be ‘leased’ to other Clouds for business consideration. In federation story, client requests can always be served, even if the target Cloud is already saturated. Home Cloud is able to serve more customers than its original capacity through ‘borrowing’ resources. And free resources can also be ‘leased’ outside, which is better than either leaving it running idly or simply shutting it down. But it also due to some problems such as the chaos of dependency relationships, too much resource debris, etc. These can lead to the decrease of resource utilities, so we should try to avoid and solve these problems.
Basic Model
If we take a look at a Cloud in Cloud Federation, we can roughly divided it into three parts, named OutRent part, Local part and Free part respectively. Because we are concentrating on the resource arrangement in a Cloud, it is sensible to regard Cloud as the collection of all resources. In the first formula of this model, we use Rf to represent free resources in a Cloud, Rw to represent the total resources in a Cloud and S to stand for all services, including OutRent services and Local services. Moreover, S can be further divided into three parts, So means OutRent services, Si means insourced services and Sl means Local services. It should be noted that insourced services are remote services which running on remote Cloud. But their information is saved locally, for both security and charging reasons. If there are not any OutRent services, then So is an empty stack. The same rule also happens on Sl and Si.
 Cloud Model
Cloud Model
In order to investigate the federation situation more clearly, we made a dependency diagram to show its ‘borrowing’ relationship among Clouds, in which Clouds are illustrated by a rectangle, sometimes with a unique filling color or pattern. We put a solid arrow from Cloud A to Cloud B if there exists a ‘borrowing’ relationship from Cloud A to Cloud B, or said, Cloud A uses some part of the resources from Cloud B by redirecting client requests or copying compiled source codes and running remotely. Such diagram is called ‘Resource Dependency Flow’ in Cloud Federation which is shown in figure 1.
 Figure 1
Figure 1
In Resource Dependency Flow Diagram (for short, RDFD), there may exist simultaneous appearances of borrowing and leasing in a Cloud. A more common situation is to form a ring, which we call it ‘resource dependency ring’. It would make a negative impact to the overall performance. Our mechanisms try to eliminate this situation along with the ring, thus improve performance of running services along with the business benefits for a Cloud provider. Figure 2 shows a common resource dependency ring in Cloud Federation. Here resource dependency ring is displayed intuitively, with several Clouds and circular arrow pointing to each other. All these three Clouds are borrowing and leasing resources at the same time. An ideal dependency relation started from Figure 2 is shown in Figure 3.
 Figure 2
Figure 2
 Figure 3
Figure 3
Approach
Scale-up Part
 Algorithm
Algorithm
Besides the algorithm, there is still a point which needs to be further discussed is that we consider a service as an entirety which cannot be divided further. No matter we decide to run it locally or remotely, it is not recommended to divide it into several pieces and located these pieces in different Clouds. An obvious shortage of this rule is the internal fragmentation, but after knowing the reasons of this rule, its disadvantage can also be accepted. It is known that application today always contains some transactions which need the manager to take some extra care. When it comes to a distributed system, this ’extra care’ will become difficult enough to make management cost boost. Consistency and deadlock are two common problems in distributed system, and the division of a service will cause these two problems, thus increasing the cost and complexity of technical management.
Scale-down Part
In the previous sub-section we have discussed our algorithm when dealing with allocating resources in a Cloud, or said scaling-up. And we want to perform the most important and only rule in scaling-down period: Moving OutRent services to local node as soon as possible. Actually, the decision about moving OutRent service to local node should also be made carefully. Although in many cases this rule will help to avoid the simultaneous appearance of borrowing and leasing, it should still be cautious to be executed in the following situations.
- Services with small-scaled data
- Services are almost completed
If a service does not need large-scaled data as its input or output, its remote execution time will not differ much comparing with its local execution time because time consumption on data transmission through network connection is not so huge. Such services contain scientific computing without much input and output, stateless web-application with little or even no database operations, etc.
According to our moving strategy shown earlier, time is mainly cost in context-switching and transmitting context information when moving OutRent services to local Cloud. But if a service is almost completed, it is recommended to wait for its completion. More specific, if the sum of context-switching time and transmitting context information time is bigger than the rest renting time, moving is unnecessary. Further, because the time consumption of context-switching and transmitting context information is quite stable, it is reasonable to consider it as a constant. In other word, user or Cloud provider can set a threshold to represent this constant. Once the left renting time is smaller than this threshold, moving it back will be rejected by the resource manager layer.
Evaluation
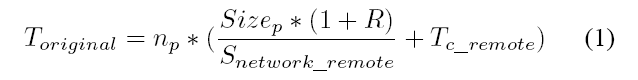
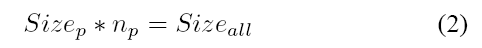


The improvement percentage between optimized time consumption and original one ranges around 10% to 20%, which is a real great promotion. So we want to point out here that the results shown in the table is the maximum improvement of each condition. If we think about the calculation formula again, we can find that this calculation is based on the moment when services begins. In most cases we need to make this type of optimization decision in the middle of services’ running period, which means the improvement percentage cannot be so great. Besides, it has already been shown that there exists a threshold and it will be meaningless to make optimization when the left running time is less than this threshold. So an important conclusion of this optimization is that the less the running time is left, the less the improvement percentage will be.